Recommended Architecture
We recommend all developers using LiveAvatar to follow this high level approach. Set up both a backend and frontend services.
- Have the backend initiate and track the session state as it occurs
- Have the frontend manage the users respective responses and interactions.
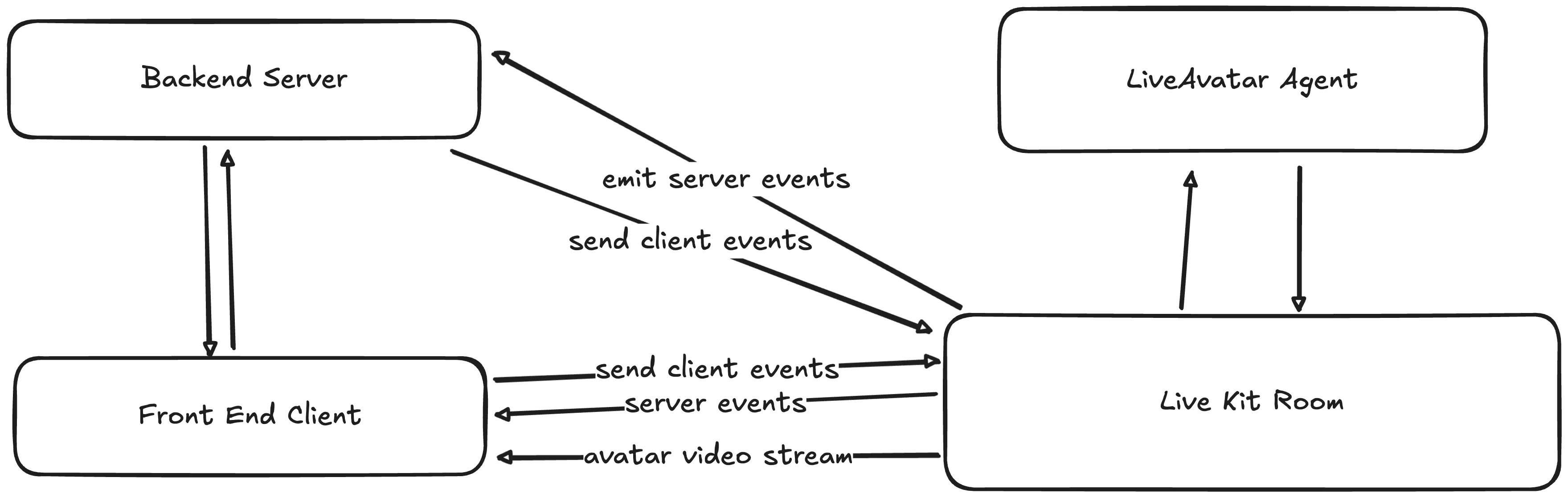
The main developer experience is revolved around the events being sent to/from the LiveKit room. By sending client events and listening to server events, developers can both monitor and control exactly what and how the Avatar response.
Limited Existing Conversational Stack
If you don't have an existing LLM + Voice (VAD + TTS) stack or a few existing pieces, we recommend using FULL mode. A few calls to instantiate the session is all that is required by your backend server. We recommend building out the user experience on the frontend instead, leveraging our low latencies to immediately change the state.
Existing Developers Conversation Stack
We recommend developing with CUSTOM mode. Have your backend process the user input audio, and generate a custom response with whichever frameworks you want. Then send the outputted audio directly into LiveAvatar.
Using Custom, you should have full control over all services in your conversation stack. We will now expose a websocket link after starting a sesison.
We recommend establishing a connection with your backend service and streaming the output of your audio directly into our websocket. We'll stream back the generated avatar frame data that you can then send to your application.
Updated about 2 months ago